10 minutes to read
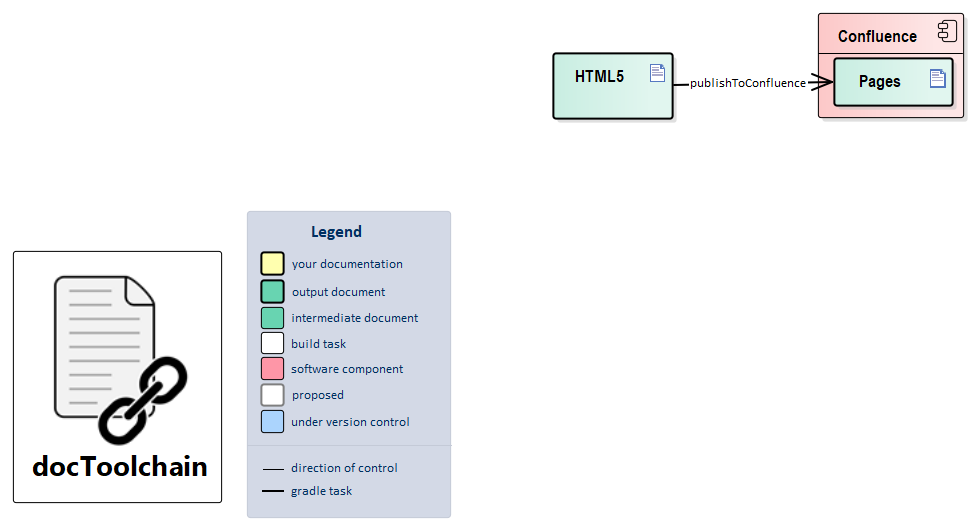
publishToConfluence
At a Glance
About This Task
This task takes a generated HTML file, splits it by headline, and pushes it to your instance of Confluence. This lets you use the docs-as-code approach even if your organisation insists on using Confluence as its main document repository.
|
Note
|
From the 01.01.2024 on, Atlassian turns off API V1 for Confluence Cloud, if there is a V2 equivalent. docToolchain versions from 3.1 on support API V2. If you are using an older version of docToolchain, you’ll need to upgrade to a newer version.
To enable API V2, set |
|
Note
|
Currently, docToolchain only has full support for the old Confluence editor. The new editor is not fully supported yet. You can use the new editor, but you may experience some unexpected layout issues/ changes. To make use of the new editor you need to set |
Special Features
Easy Code Block Conversion
[source]-blocks are converted to code-macro blocks in Confluence.
Confluence supports a very limited list of languages supported for code block syntax highlighting. When specifying an unknown language, it would even display an error. Therefore, some transformation is applied.
-
If no language is given in the source block, it is explicitly set to plain text (because the default would be Java that might not always apply).
-
Some known and common AsciiDoc source languages are mapped to Confluence code block languages.
source target note json
yml
produces an acceptable highlighting
shell
bash
only a specific shell is supported
yaml
yml
different name of language
-
If the language of the source block is not supported by Confluence, it is set to plain text as fallback to avoid the error.
|
Note
|
Get a list of valid languages (and learn how to add others) here. |
Minimal Impact on Non-Techie Confluence Users
Only pages and images that changed between task runs are published, and only those changes are notified to page watchers, cutting down on 'spam'.
Keywords Automatically Attached as Labels
:keywords: are attached as labels to every Confluence page generated using the publishToConfluence task.
See Atlassian’s own guidelines on labels.
Several keywords are allowed, and they must be separated by commas. For example: :keywords: label_1, label-2, label3, ….
Labels (keywords) must not contain a space character. Use either '_' or '-'.
Configuration
You configure the publishToConfluence task in the file docToolchainConfig.groovy. It is located in the root of your project folder. We try to make the configuration self-explanatory, but below is some more information about each config option.
input
is an array of files to upload to Confluence with the ability to configure a different parent page for each file.
Attributes
-
file: absolute or relative path to the asciidoc generated html file to be exported -
url: absolute URL to an asciidoc generated html file to be exported -
ancestorName(optional): the name of the parent page in Confluence as string; this attribute has priority over ancestorId, but if page with given name doesn’t exist, ancestorId will be used as a fallback -
ancestorId(optional): the id of the parent page in Confluence as string; leave this empty if a new parent shall be created in the space
The following four keys can also be used in the global section below
-
spaceKey(optional): page specific variable for the key of the confluence space to write to -
subpagesForSections(optional): The number of nested sub-pages to create. Default is '1'. '0' means creating all on one page. The following migration for removed configuration can be used.-
allInOnePage = trueis the same assubpagesForSections = 0 -
allInOnePage = false && createSubpages = falseis the same assubpagesForSections = 1 -
allInOnePage = false && createSubpages = trueis the same assubpagesForSections = 2
-
-
pagePrefix(optional): page specific variable, the pagePrefix will be a prefix for the page title and it’s sub-pages use this if you only have access to one confluence space but need to store several pages with the same title - a different pagePrefix will make them unique -
pageSuffix(optional): same usage as prefix but appended to the title and it’s subpages
only 'file' or 'url' is allowed. If both are given, 'url' is ignored
ancestorId
The page ID of the parent page where you want your docs to be published. Go to this page, click Edit and the required ID will show up in the URL. Specify the ID as a string within the config file.
api
Endpoint of the confluenceAPI (REST) to be used and looks like https://[yourServer]/[context], while [context] is optional.
If you use Confluence Cloud, you can omit the context.
If you use Confluence Server, you may need to set a context, depending on your Confluence configuration.
rateLimit (since 3.2.0), The rate limit for Confluence requests. Default is 10 requests per second.
useV1Api
This feature is available for docToolchain >= 3.1 only
|
Note
|
If you set this to false, ensure the api config is set to https://[yourCloudDomain]. (Mind no context given here)
|
If you are using Confluence Cloud, you can set this to false to use the new API V2. If you are using Confluence Server, you can set this to true to use the old API V1. If you are using Confluence Cloud and set this to false, you will get an error message, once Atlassian turns off API V1 (starting 01.01.2024).
enforceNewEditor
Atlassian is currently rolling out a new editor for Confluence. If you want to use the new editor, you can set this to true. If you are using the old editor, you can set this to false. If you are using the new editor, you may experience some unexpected layout issues/ changes, since the new editor has yet no feature parity and therefore may be incompatible.
disableToC
This boolean configuration determines whether the table of contents (ToC) is disabled on the page once uploaded to Confluence. false by default, so the ToC is active.
pagePrefix/pageSuffix
Confluence can’t handle two pages with the same name - even with different casing (lowercase, UPPERCASE, a mix).
This script matches pages regardless of case and refuses to replace a page whose name differs from an existing page only by casing.
Ideally, you should create a new Confluence space for each piece of larger documentation.
If you are restricted and can’t create new spaces, you can use pagePrefix/pageSuffix to define a prefix/suffix for the doc so that it doesn’t conflict with other page names.
pageVersionComment
Set an optional comment for the new page version in Confluence.
credentials
For security reasons it is highly recommended to store your credentials in a separate file outside the Git repository, such as in your Home folder.
To authenticate with username and API token, use: credentials = "user:${new File("/users/me/apitoken").text}" or credentials = "user:${new File("/users/me/apitoken").text}"`.bytes.encodeBase64().toString()` to …….. You can create an API-token in your profile.
To authenticate with username and password, use: credentials = ……
You can also set your username, password of apitoken as an environment variable. You then do the following: 1. Open the file that contains the environment variables: a. On a Mac, go to your Home folder and open the file .zpfrofile. 2. ….
If you wish to simplify the injection of credentials from external sources, do the following:
1. In docToolchainConfig.groovy, do not enter the credentials. Make sure the credentials are escaped.
2. Create a gradle.properties file in the project or home directory. See the gradle user guide.
3. Open the file, and put the variables in it:
- confluenceUser=myusername, and on a new line
- confluencePass=myuserpassword
apikey
In situations where you have to use full user authorisation because of internal Confluence permission handling, you’ll need to add the API-token in addition to the credentials.
The API-token cannot be added to the credentials because it’s used for user and password exchange.
Therefore the API-token can be added as parameter apikey, which makes the addition of the token a separate header field with key: keyId and value of apikey.
An example (including storing of the real value outside this configuration) is: apikey = "${new File("/home/me/apitoken").text}".
bearerToken
You can pass a Confluence
Personal Access Token as the bearerToken. It is an alternative to
credentials. Do not confuse it with apiKey.
extraPageContent
If you need to prefix your pages with a warning stating that 'this is generated content', this is where you do it.
enableAttachments
If value is set to true, any links to local file references will be uploaded as attachments. The current implementation only supports a single folder, the name of which will be used as a prefix to validate whether or not your file should be uploaded.
If you enable this feature, and use a folder which starts with 'attachment', an adaption of this prefix is required.
pageLimit
Limits the number of pages retrieved from the server to check if a page with this name already exists.
jiraServerId
Stores the Jira server ID that your Confluence instance is connected to. If a value is set, all anchors pointing to a Jira ticket will be replaced by the Confluence Jira macro.
To function properly, jiraRoot must be configured (see exportJiraIssues). Here’s an example:
All files to attach will need to be linked inside the document:
link:attachment/myfolder/myfile.json[My API definition]
attachmentPrefix
Stores the expected foldername of your output directory. Default is attachment.
proxy
If you need to provide proxy to access Confluence, you can set a map with the keys host (e.g. 'my.proxy.com'), port (e.g. '1234') and schema (e.g. 'http') of your proxy.
useOpenapiMacro
If this option is present and equal to confluence-open-api or swagger-open-api then any source block marked with class openapi will be wrapped in the Elitesoft Swagger Editor macro (see Elitesoft Swagger Editor). The key depends on the version of the macro.
For backward compatibility, if this option is present and equal to true, then again the Elitesoft Swagger Editor macro will be used.
If this option is present and equal to "open-api" then any source block marked with class openapi will be wrapped in Open API Documentation for Confluence macro: (see Open API Documentation for Confluence). A download source (yaml) button is shown by default.
Using the plugin can be handled on different ways.
-
copy/paste the content of the YAML file to the plugin without linking to the origin source by using the url to the YAML file
[source.openapi,yaml]
----
\include::https://my-domain.com/path-to-yaml[]
-----
copy/paste the content of the YAML file to the plugin without linking to the origin source by using a YAML file in your project structure:
[source.openapi,yaml]
----
\include::my-yaml-file.yaml[]
-----
create a link between the plugin and the YAML file without copying the content into the plugin. The advantage following this way is that even in case the API specification is changed without re-generating the documentation, the new version of the configuration is used in Confluence.
[source.openapi,yaml,role="url:https://my-domain.com/path-to-yaml"]
----
\include::https://my-domain.com/path-to-yaml[]
----publishToConfluence.gradle
//Configureation for publishToConfluence
confluence = [:]
// 'input' is an array of files to upload to Confluence with the ability
// to configure a different parent page for each file.
//
// Attributes
// - 'file': absolute or relative path to the asciidoc generated html file to be exported
// - 'url': absolute URL to an asciidoc generated html file to be exported
// - 'ancestorName' (optional): the name of the parent page in Confluence as string;
// this attribute has priority over ancestorId, but if page with given name doesn't exist,
// ancestorId will be used as a fallback
// - 'ancestorId' (optional): the id of the parent page in Confluence as string; leave this empty
// if a new parent shall be created in the space
// Set it for every file so the page scanning is done only for the given ancestor page trees.
//
// The following four keys can also be used in the global section below
// - 'spaceKey' (optional): page specific variable for the key of the confluence space to write to
// - 'subpagesForSections' (optional): The number of nested sub-pages to create. Default is '1'.
// '0' means creating all on one page.
// The following migration for removed configuration can be used.
// 'allInOnePage = true' is the same as 'subpagesForSections = 0'
// 'allInOnePage = false && createSubpages = false' is the same as 'subpagesForSections = 1'
// 'allInOnePage = false && createSubpages = true' is the same as 'subpagesForSections = 2'
// - 'pagePrefix' (optional): page specific variable, the pagePrefix will be a prefix for the page title and it's sub-pages
// use this if you only have access to one confluence space but need to store several
// pages with the same title - a different pagePrefix will make them unique
// - 'pageSuffix' (optional): same usage as prefix but appended to the title and it's subpages
// only 'file' or 'url' is allowed. If both are given, 'url' is ignored
confluence.with {
input = [
[ file: "build/docs/html5/arc42-template-de.html" ],
]
// endpoint of the confluenceAPI (REST) to be used
// https://[yourServer]
api = 'https://[yourServer]'
// requests per second for confluence API calls
rateLimit = 10
// Additionally, spaceKey, subpagesForSections, pagePrefix and pageSuffix can be globally defined here. The assignment in the input array has precedence
// the key of the confluence space to write to
spaceKey = 'asciidoc'
// if true, all pages will be created using the new editor v2
// enforceNewEditor = false
// variable to determine how many layers of sub pages should be created
subpagesForSections = 1
// the pagePrefix will be a prefix for each page title
// use this if you only have access to one confluence space but need to store several
// pages with the same title - a different pagePrefix will make them unique
pagePrefix = ''
pageSuffix = ''
/*
WARNING: It is strongly recommended to store credentials securely instead of commiting plain text values to your git repository!!!
Tool expects credentials that belong to an account which has the right permissions to to create and edit confluence pages in the given space.
Credentials can be used in a form of:
- passed parameters when calling script (-PconfluenceUser=myUsername -PconfluencePass=myPassword) which can be fetched as a secrets on CI/CD or
- gradle variables set through gradle properties (uses the 'confluenceUser' and 'confluencePass' keys)
Often, same credentials are used for Jira & Confluence, in which case it is recommended to pass CLI parameters for both entities as
-Pusername=myUser -Ppassword=myPassword
*/
//optional API-token to be added in case the credentials are needed for user and password exchange.
//apikey = "[API-token]"
// HTML Content that will be included with every page published
// directly after the TOC. If left empty no additional content will be
// added
// extraPageContent = '<ac:structured-macro ac:name="warning"><ac:parameter ac:name="title" /><ac:rich-text-body>This is a generated page, do not edit!</ac:rich-text-body></ac:structured-macro>
extraPageContent = ''
// enable or disable attachment uploads for local file references
enableAttachments = false
// default attachmentPrefix = attachment - All files to attach will require to be linked inside the document.
// attachmentPrefix = "attachment"
// Optional proxy configuration, only used to access Confluence
// schema supports http and https
// proxy = [host: 'my.proxy.com', port: 1234, schema: 'http']
// Optional: specify which Confluence OpenAPI Macro should be used to render OpenAPI definitions
// possible values: ["confluence-open-api", "open-api", "swagger-open-api", true]. true is the same as "confluence-open-api" for backward compatibility
// useOpenapiMacro = "confluence-open-api"
}CSS Styling
Some AsciiDoctor features depend on specific CSS style definitions. Unless these styles are defined, some formatting that is present in the HTML version will not be represented when published to Confluence. To configure Confluence to include additional style definitions:
-
Log in to Confluence as a space admin.
-
Go to the desired space.
-
Select Space tools > Look and Feel > Stylesheet.
-
Click Edit then enter the desired style definitions.
-
Click Save.
The default style definitions can be found in the AsciiDoc project as asciidoctor-default.css. You will most likely NOT want to include the entire thing, as some of the definitions are likely to disrupt Confluence’s layout.
The following style definitions are Confluence-compatible, and will enable the use of the built-in roles (big/small, underline/overline/line-through, COLOR/COLOR-background for the sixteen HTML color names):
.big{font-size:larger}
.small{font-size:smaller}
.underline{text-decoration:underline}
.overline{text-decoration:overline}
.line-through{text-decoration:line-through}
.aqua{color:#00bfbf}
.aqua-background{background-color:#00fafa}
.black{color:#000}
.black-background{background-color:#000}
.blue{color:#0000bf}
.blue-background{background-color:#0000fa}
.fuchsia{color:#bf00bf}
.fuchsia-background{background-color:#fa00fa}
.gray{color:#606060}
.gray-background{background-color:#7d7d7d}
.green{color:#006000}
.green-background{background-color:#007d00}
.lime{color:#00bf00}
.lime-background{background-color:#00fa00}
.maroon{color:#600000}
.maroon-background{background-color:#7d0000}
.navy{color:#000060}
.navy-background{background-color:#00007d}
.olive{color:#606000}
.olive-background{background-color:#7d7d00}
.purple{color:#600060}
.purple-background{background-color:#7d007d}
.red{color:#bf0000}
.red-background{background-color:#fa0000}
.silver{color:#909090}
.silver-background{background-color:#bcbcbc}
.teal{color:#006060}
.teal-background{background-color:#007d7d}
.white{color:#bfbfbf}
.white-background{background-color:#fafafa}
.yellow{color:#bfbf00}
.yellow-background{background-color:#fafa00}Source
publishToConfluence.gradle
task publishToConfluence(
description: 'publishes the HTML rendered output to confluence',
group: 'docToolchain'
) {
doLast {
logger.info("docToolchain> docDir: "+docDir)
config.confluence.api = findProperty("confluence.api")?:config.confluence.api
//TODO default should be false, if the V1 has been removed in cloud
config.confluence.useV1Api = findProperty("confluence.useV1Api") != null ?
findProperty("confluence.useV1Api") : config.confluence.useV1Api != [:] ?
config.confluence.useV1Api :true
binding.setProperty('config',config)
binding.setProperty('docDir',docDir)
evaluate(new File(projectDir, 'core/src/main/groovy/org/docToolchain/scripts/asciidoc2confluence.groovy'))
}
}scripts/org/docToolchain/scripts/asciidoc2confluence.groovy
package org.docToolchain.scripts
import org.docToolchain.atlassian.transformer.HtmlTransformer
/**
* Created by Ralf D. Mueller and Alexander Heusingfeld
* https://github.com/rdmueller/asciidoc2confluence
*
* this script expects an HTML document created with AsciiDoctor
* in the following style (default AsciiDoctor output)
* <div class="sect1">
* <h2>Page Title</h2>
* <div class="sectionbody">
* <div class="sect2">
* <h3>Sub-Page Title</h3>
* </div>
* <div class="sect2">
* <h3>Sub-Page Title</h3>
* </div>
* </div>
* </div>
* <div class="sect1">
* <h2>Page Title</h2>
* ...
* </div>
*
*/
/*
Additions for issue #342 marked as #342-dierk42
;-)
*/
// some dependencies
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
import org.jsoup.nodes.TextNode
import org.jsoup.select.Elements
import groovy.transform.Field
import java.nio.file.Path
import java.security.MessageDigest
import static groovy.io.FileType.FILES
import org.docToolchain.atlassian.confluence.clients.ConfluenceClientV1
import org.docToolchain.atlassian.confluence.clients.ConfluenceClientV2
import org.docToolchain.configuration.ConfigService
import org.docToolchain.atlassian.confluence.ConfluenceService
@Field
ConfigService configService = new ConfigService(config)
@Field
ConfluenceService confluenceService = new ConfluenceService(configService)
@Field
def confluenceClient = configService.getConfigProperty("confluence.useV1Api") ?
new ConfluenceClientV1(configService) :
new ConfluenceClientV2(configService)
@Field
def CDATA_PLACEHOLDER_START = '<cdata-placeholder>'
@Field
def CDATA_PLACEHOLDER_END = '</cdata-placeholder>'
@Field
def baseUrl
def allPages
// #938-mksiva: global variable to hold input spaceKey passed in the Config.groovy
def spaceKeyInput
// configuration
def confluenceSpaceKey
def confluenceSubpagesForSections
@Field
def confluencePagePrefix
@Field
def confluencePageSuffix
//def baseApiPath = new URI(config.confluence.api).path
// helper functions
def MD5(String s) {
MessageDigest.getInstance("MD5").digest(s.bytes).encodeHex().toString()
}
def parseAdmonitionBlock(block, String type) {
content = block.select(".content").first()
titleElement = content.select(".title")
titleText = ''
if(titleElement != null) {
titleText = "<ac:parameter ac:name=\"title\">${titleElement.text()}</ac:parameter>"
titleElement.remove()
}
block.after("<ac:structured-macro ac:name=\"${type}\">${titleText}<ac:rich-text-body>${content}</ac:rich-text-body></ac:structured-macro>")
block.remove()
}
/* #342-dierk42
add labels to a Confluence page. Labels are taken from :keywords: which
are converted as meta tags in HTML. Building the array: see below
Confluence allows adding labels only after creation of a page.
Therefore we need extra API calls.
Currently the labels are added one by one. Suggestion for improvement:
Build a label structure of all labels an place them with one call.
Replaces exisiting labels. No harm
Does not check for deleted labels when keywords are deleted from source
document!
*/
def addLabels = { def pageId, def labelsArray ->
// Attach each label in a API call of its own. The only prefix possible
// in our own Confluence is 'global'
labelsArray.each { label ->
label_data = [
prefix : 'global',
name : label
]
confluenceClient.addLabel(pageId, label_data)
println "added label " + label + " to page ID " + pageId
}
}
def uploadAttachment = { def pageId, String url, String fileName, String note ->
def is
def localHash
if (url.startsWith('http')) {
is = new URL(url).openStream()
//build a hash of the attachment
localHash = MD5(new URL(url).openStream().text)
} else {
is = new File(url).newDataInputStream()
//build a hash of the attachment
localHash = MD5(new File(url).newDataInputStream().text)
}
def attachment = confluenceClient.getAttachment(pageId, fileName)
if (attachment.size()>0 && attachment.results.size()>0) {
// attachment exists. need an update?
if (confluenceClient.attachmentHasChanged(attachment, localHash)) {
//hash is different -> attachment needs to be updated
confluenceClient.updateAttachment(pageId, attachment.results[0].id, is, fileName, note, localHash)
println " updated attachment"
}
} else {
confluenceClient.createAttachment(pageId, is, fileName, note, localHash)
}
}
def realTitle(pageTitle){
confluencePagePrefix + pageTitle + confluencePageSuffix
}
def rewriteMarks (body) {
// Confluence strips out mark elements. Replace them with default formatting.
body.select('mark').wrap('<span style="background:#ff0;color:#000"></style>').unwrap()
}
// #352-LuisMuniz: Helper methods
// Fetch all pages of the defined config ancestorsIds. Only keep relevant info in the pages Map
// The map is indexed by lower-case title
def retrieveAllPages = { String spaceKey ->
// #938-mksiva: added a condition spaceKeyInput is null, if it is null, it means that, space key is different, so re fetch all pages.
if (allPages != null && spaceKeyInput == null) {
println "allPages already retrieved"
allPages
} else {
def pageIds = []
def checkSpace = false
int pageLimit = config.confluence.pageLimit ? config.confluence.pageLimit : 100
config.confluence.input.each { input ->
if (!input.ancestorId) {
// if one ancestorId is missing we should scan the whole space
checkSpace = true;
return
}
pageIds.add(input.ancestorId)
}
println (".")
if(checkSpace) {
allPages = confluenceClient.fetchPagesBySpaceKey(spaceKey, pageLimit)
} else {
allPages = confluenceClient.fetchPagesByAncestorId(pageIds, pageLimit)
}
allPages
}
}
// Retrieve a page by id with contents and version
def retrieveFullPage = { String id ->
println("retrieving page with id " + id)
confluenceClient.retrieveFullPageById(id)
}
//if a parent has been specified, check whether a page has the same parent.
boolean hasRequestedParent(Map existingPage, String requestedParentId) {
if (requestedParentId) {
existingPage.parentId == requestedParentId
} else {
true
}
}
def rewriteDescriptionLists(body) {
def TAGS = [ dt: 'th', dd: 'td' ]
body.select('dl').each { dl ->
// WHATWG allows wrapping dt/dd in divs, simply unwrap them
dl.select('div').each { it.unwrap() }
// group dts and dds that belong together, usually it will be a 1:1 relation
// but HTML allows for different constellations
def rows = []
def current = [dt: [], dd: []]
rows << current
dl.select('dt, dd').each { child ->
def tagName = child.tagName()
if (tagName == 'dt' && current.dd.size() > 0) {
// dt follows dd, start a new group
current = [dt: [], dd: []]
rows << current
}
current[tagName] << child.tagName(TAGS[tagName])
child.remove()
}
rows.each { row ->
def sizes = [dt: row.dt.size(), dd: row.dd.size()]
def rowspanIdx = [dt: -1, dd: sizes.dd - 1]
def rowspan = Math.abs(sizes.dt - sizes.dd) + 1
def max = sizes.dt
if (sizes.dt < sizes.dd) {
max = sizes.dd
rowspanIdx = [dt: sizes.dt - 1, dd: -1]
}
(0..<max).each { idx ->
def tr = dl.appendElement('tr')
['dt', 'dd'].each { type ->
if (sizes[type] > idx) {
tr.appendChild(row[type][idx])
if (idx == rowspanIdx[type] && rowspan > 1) {
row[type][idx].attr('rowspan', "${rowspan}")
}
} else if (idx == 0) {
tr.appendElement(TAGS[type]).attr('rowspan', "${rowspan}")
}
}
}
}
dl.wrap('<table></table>')
.unwrap()
}
}
def rewriteInternalLinks (body, anchors, pageAnchors) {
// find internal cross-references and replace them with link macros
body.select('a[href]').each { a ->
def href = a.attr('href')
if (href.startsWith('#')) {
def anchor = href.substring(1)
def pageTitle = anchors[anchor] ?: pageAnchors[anchor]
if (pageTitle && a.text()) {
// as Confluence insists on link texts to be contained
// inside CDATA, we have to strip all HTML and
// potentially loose styling that way.
a.html(a.text())
a.wrap("<ac:link${anchors.containsKey(anchor) ? ' ac:anchor="' + anchor + '"' : ''}></ac:link>")
.before("<ri:page ri:content-title=\"${realTitle pageTitle}\"/>")
.wrap("<ac:plain-text-link-body>${CDATA_PLACEHOLDER_START}${CDATA_PLACEHOLDER_END}</ac:plain-text-link-body>")
.unwrap()
}
}
}
}
def rewriteJiraLinks = { body ->
// find links to jira tickets and replace them with jira macros
body.select('a[href]').each { a ->
def href = a.attr('href')
if (href.startsWith(config.jira.api + "/browse/")) {
def ticketId = a.text()
a.before("""<ac:structured-macro ac:name=\"jira\" ac:schema-version=\"1\">
<ac:parameter ac:name=\"key\">${ticketId}</ac:parameter>
<ac:parameter ac:name=\"serverId\">${config.confluence.jiraServerId}</ac:parameter>
</ac:structured-macro>""")
a.remove()
}
}
}
def rewriteOpenAPI (org.jsoup.nodes.Element body) {
if (config.confluence.useOpenapiMacro == true || config.confluence.useOpenapiMacro == 'confluence-open-api') {
body.select('div.openapi pre > code').each { code ->
def parent=code.parent()
def rawYaml=code.wholeText()
code.parent()
.wrap('<ac:structured-macro ac:name="confluence-open-api" ac:schema-version="1" ac:macro-id="1dfde21b-6111-4535-928a-470fa8ae3e7d"></ac:structured-macro>')
.unwrap()
code.wrap("<ac:plain-text-body>${CDATA_PLACEHOLDER_START}${CDATA_PLACEHOLDER_END}</ac:plain-text-body>")
.replaceWith(new TextNode(rawYaml))
}
} else if (config.confluence.useOpenapiMacro == 'swagger-open-api') {
body.select('div.openapi pre > code').each { code ->
def parent=code.parent()
def rawYaml=code.wholeText()
code.parent()
.wrap('<ac:structured-macro ac:name="swagger-open-api" ac:schema-version="1" ac:macro-id="f9deda8a-1375-4488-8ca5-3e10e2e4ee70"></ac:structured-macro>')
.unwrap()
code.wrap("<ac:plain-text-body>${CDATA_PLACEHOLDER_START}${CDATA_PLACEHOLDER_END}</ac:plain-text-body>")
.replaceWith(new TextNode(rawYaml))
}
} else if (config.confluence.useOpenapiMacro == 'open-api') {
def includeURL=null
for (Element e : body.select('div .listingblock.openapi')) {
for (String s : e.className().split(" ")) {
if (s.startsWith("url")) {
//include the link to the URL for the macro
includeURL = s.replace('url:', '')
}
}
}
body.select('div.openapi pre > code').each { code ->
def parent=code.parent()
def rawYaml=code.wholeText()
code.parent()
.wrap('<ac:structured-macro ac:name="open-api" ac:schema-version="1" data-layout="default" ac:macro-id="4302c9d8-fca4-4f14-99a9-9885128870fa"></ac:structured-macro>')
.unwrap()
if (includeURL!=null)
{
code.before('<ac:parameter ac:name="url">'+includeURL+'</ac:parameter>')
}
else {
//default: show download button
code.before('<ac:parameter ac:name="showDownloadButton">true</ac:parameter>')
code.wrap("<ac:plain-text-body>${CDATA_PLACEHOLDER_START}${CDATA_PLACEHOLDER_END}</ac:plain-text-body>")
.replaceWith(new TextNode(rawYaml))
}
}
}
}
def getEmbeddedImageData(src){
def imageData = src.split("[;:,]")
def fileExtension = imageData[1].split("/")[1]
// treat svg+xml as svg to be able to create a file from the embedded image
// more MIME types: https://www.iana.org/assignments/media-types/media-types.xhtml#image
if(fileExtension == "svg+xml"){
fileExtension = "svg"
}
return Map.of(
"fileExtension", fileExtension,
"encoding", imageData[2],
"encodedContent", imageData[3]
)
}
def handleEmbeddedImage(basePath, fileName, fileExtension, encodedContent) {
def imageDir = "images/"
if(config.imageDirs.size() > 0){
def dir = config.imageDirs.find { it ->
def configureImagesDir = it.replace('./', '/')
Path.of(basePath, configureImagesDir, fileName).toFile().exists()
}
if(dir != null){
imageDir = dir.replace('./', '/')
}
}
if(!Path.of(basePath, imageDir, fileName).toFile().exists()){
println "Could not find embedded image at a known location"
def embeddedImagesLocation = "/confluence/images/"
new File(basePath + embeddedImagesLocation).mkdirs()
def imageHash = MD5(encodedContent)
println "Embedded Image Hash " + imageHash
def image = new File(basePath + embeddedImagesLocation + imageHash + ".${fileExtension}")
if(!image.exists()){
println "Creating image at " + basePath + embeddedImagesLocation
image.withOutputStream {output ->
output.write(encodedContent.decodeBase64())}
}
fileName = imageHash + ".${fileExtension}"
return Map.of(
"filePath", image.canonicalPath,
"fileName", fileName
)
} else {
return Map.of(
"filePath", basePath + imageDir + fileName,
"fileName", fileName
)
}
}
//modify local page in order to match the internal confluence storage representation a bit better
//definition lists are not displayed by confluence, so turn them into tables
//body can be of type Element or Elements
def parseBody(body, anchors, pageAnchors) {
def uploads = []
rewriteOpenAPI body
body.select('div.paragraph').unwrap()
body.select('div.ulist').unwrap()
//body.select('div.sect3').unwrap()
[ 'note':'info',
'warning':'warning',
'important':'warning',
'caution':'note',
'tip':'tip' ].each { adType, cType ->
body.select('.admonitionblock.'+adType).each { block ->
parseAdmonitionBlock(block, cType)
}
}
//special for the arc42-template
body.select('div.arc42help').select('.content')
.wrap('<ac:structured-macro ac:name="expand"></ac:structured-macro>')
.wrap('<ac:rich-text-body></ac:rich-text-body>')
.wrap('<ac:structured-macro ac:name="info"></ac:structured-macro>')
.before('<ac:parameter ac:name="title">arc42</ac:parameter>')
.wrap('<ac:rich-text-body><p></p></ac:rich-text-body>')
body.select('div.arc42help').unwrap()
body.select('div.title').wrap("<strong></strong>").before("<br />").wrap("<div></div>")
body.select('div.listingblock').wrap("<p></p>").unwrap()
// see if we can find referenced images and fetch them
new File("tmp/images/.").mkdirs()
// find images, extract their URLs for later uploading (after we know the pageId) and replace them with this macro:
// <ac:image ac:align="center" ac:width="500">
// <ri:attachment ri:filename="deployment-context.png"/>
// </ac:image>
body.select('img').each { img ->
def src = img.attr('src')
def imgWidth = img.attr('width')?:500
def imgAlign = img.attr('align')?:"center"
//it is not an online image, so upload it to confluence and use the ri:attachment tag
if(!src.startsWith("http")) {
def sanitizedBaseUrl = baseUrl.toString().replaceAll('\\\\','/').replaceAll('/[^/]*$','/')
def newUrl
def fileName
//it is an embedded image
if(src.startsWith("data:image")){
def imageData = getEmbeddedImageData(src)
def fileExtension = imageData.get("fileExtension")
def encodedContent = imageData.get("encodedContent")
fileName = img.attr('alt').replaceAll(/\s+/,"_").concat(".${fileExtension}")
def embeddedImage = handleEmbeddedImage(sanitizedBaseUrl, fileName, fileExtension, encodedContent)
newUrl = embeddedImage.get("filePath")
fileName = embeddedImage.get("fileName")
}else {
newUrl = sanitizedBaseUrl + src
fileName = java.net.URLDecoder.decode((src.tokenize('/')[-1]),"UTF-8")
}
newUrl = java.net.URLDecoder.decode(newUrl,"UTF-8")
println " image: "+newUrl
uploads << [0,newUrl,fileName,"automatically uploaded"]
img.after("<ac:image ac:align=\"${imgAlign}\" ac:width=\"${imgWidth}\"><ri:attachment ri:filename=\"${fileName}\"/></ac:image>")
}
// it is an online image, so we have to use the ri:url tag
else {
img.after("<ac:image ac:align=\"imgAlign\" ac:width=\"${imgWidth}\"><ri:url ri:value=\"${src}\"/></ac:image>")
}
img.remove()
}
if(config.confluence.enableAttachments){
attachmentPrefix = config.confluence.attachmentPrefix ? config.confluence.attachmentPrefix : 'attachment'
body.select('a').each { link ->
def src = link.attr('href')
println " attachment src: "+src
//upload it to confluence and use the ri:attachment tag
if(src.startsWith(attachmentPrefix)) {
def newUrl = baseUrl.toString().replaceAll('\\\\','/').replaceAll('/[^/]*$','/')+src
def fileName = java.net.URLDecoder.decode((src.tokenize('/')[-1]),"UTF-8")
newUrl = java.net.URLDecoder.decode(newUrl,"UTF-8")
uploads << [0,newUrl,fileName,"automatically uploaded non-image attachment by docToolchain"]
def uriArray=fileName.split("/")
def pureFilename = uriArray[uriArray.length-1]
def innerhtml = link.html()
link.after("<ac:structured-macro ac:name=\"view-file\" ac:schema-version=\"1\"><ac:parameter ac:name=\"name\"><ri:attachment ri:filename=\"${pureFilename}\"/></ac:parameter></ac:structured-macro>")
link.after("<ac:link><ri:attachment ri:filename=\"${pureFilename}\"/><ac:plain-text-link-body> <![CDATA[\"${innerhtml}\"]]></ac:plain-text-link-body></ac:link>")
link.remove()
}
}
}
if(config.confluence.jiraServerId){
rewriteJiraLinks body
}
rewriteMarks body
rewriteDescriptionLists body
rewriteInternalLinks body, anchors, pageAnchors
//not really sure if must check here the type
String bodyString = body
if(body instanceof Element){
bodyString = body.html()
}
Element saneHtml = new Document("").outputSettings(new Document.OutputSettings().prettyPrint(false)).html(bodyString)
def pageString = new HtmlTransformer().transformToConfluenceFormat(saneHtml)
return Map.of(
"page", pageString,
"uploads", uploads
)
}
def generateAndAttachToC(localPage) {
def content
if(config.confluence.disableToC){
def prefix = (config.confluence.extraPageContent?:'')
content = prefix+localPage
}else{
def default_toc = '<p><ac:structured-macro ac:name="toc"/></p>'
def prefix = (config.confluence.tableOfContents?:default_toc)+(config.confluence.extraPageContent?:'')
content = prefix+localPage
def default_children = '<p><ac:structured-macro ac:name="children"><ac:parameter ac:name="sort">creation</ac:parameter></ac:structured-macro></p>'
content += (config.confluence.tableOfChildren?:default_children)
}
def localHash = MD5(localPage)
content += '<ac:placeholder>hash: #'+localHash+'#</ac:placeholder>'
return content
}
// the create-or-update functionality for confluence pages
// #342-dierk42: added parameter 'keywords'
def pushToConfluence = { pageTitle, pageBody, parentId, anchors, pageAnchors, keywords ->
parentId = parentId?.toString()
def deferredUpload = []
String realTitleLC = realTitle(pageTitle).toLowerCase()
String realTitle = realTitle(pageTitle)
//try to get an existing page
def parsedBody = parseBody(pageBody, anchors, pageAnchors)
localPage = parsedBody.get("page")
deferredUpload.addAll(parsedBody.get("uploads"))
def localHash = MD5(localPage)
localPage = generateAndAttachToC(localPage)
// #938-mksiva: Changed the 3rd parameter from 'config.confluence.spaceKey' to 'confluenceSpaceKey' as it was always taking the default spaceKey
// instead of the one passed in the input for each row.
def pages = retrieveAllPages(confluenceSpaceKey)
println("pages retrieved")
// println "Suche nach vorhandener Seite: " + pageTitle
Map existingPage = pages[realTitleLC]
def page
if (existingPage) {
if (hasRequestedParent(existingPage, parentId)) {
page = retrieveFullPage(existingPage.id as String)
} else {
page = null
}
} else {
page = null
}
// println "Gefunden: " + page.id + " Titel: " + page.title
if (page) {
println "found existing page: " + page.id +" version "+page.version.number
//extract hash from remote page to see if it is different from local one
def remotePage = page.body.storage.value.toString().trim()
def remoteHash = remotePage =~ /(?ms)hash: #([^#]+)#/
remoteHash = remoteHash.size()==0?"":remoteHash[0][1]
// println "remoteHash: " + remoteHash
// println "localHash: " + localHash
if (remoteHash == localHash) {
println "page hasn't changed!"
deferredUpload.each {
uploadAttachment(page?.id, it[1], it[2], it[3])
}
deferredUpload = []
// #324-dierk42: Add keywords as labels to page.
if (keywords) {
addLabels(page.id, keywords)
}
return page.id
} else {
def newPageVersion = (page.version.number as Integer) + 1
confluenceClient.updatePage(
page.id,
realTitle,
confluenceSpaceKey,
localPage,
newPageVersion,
config.confluence.pageVersionComment ?: '',
parentId
)
println "> updated page "+page.id
deferredUpload.each {
uploadAttachment(page.id, it[1], it[2], it[3])
}
deferredUpload = []
// #324-dierk42: Add keywords as labels to page.
if (keywords) {
addLabels(page.id, keywords)
}
return page.id
}
} else {
//#352-LuisMuniz if the existing page's parent does not match the requested parentId, fail
if (existingPage && !hasRequestedParent(existingPage, parentId)) {
throw new IllegalArgumentException("Cannot create page, page with the same "
+ "title=${existingPage.title} "
+ "with id=${existingPage.id} already exists in the space. "
+ "A Confluence page title must be unique within a space, consider specifying a 'confluencePagePrefix' in ConfluenceConfig.groovy")
}
//create a page
page = confluenceClient.createPage(
realTitle,
confluenceSpaceKey,
localPage,
config.confluence.pageVersionComment ?: '',
parentId
)
println "> created page "+page?.id
deferredUpload.each {
uploadAttachment(page?.id, it[1], it[2], it[3])
}
deferredUpload = []
// #324-dierk42: Add keywords as labels to page.
if (keywords) {
addLabels(page?.id, keywords)
}
return page?.id
}
}
def parseAnchors(page) {
def anchors = [:]
page.body.select('[id]').each { anchor ->
def name = anchor.attr('id')
anchors[name] = page.title
anchor.before("<ac:structured-macro ac:name=\"anchor\"><ac:parameter ac:name=\"\">${name}</ac:parameter></ac:structured-macro>")
}
anchors
}
def pushPages
pushPages = { pages, anchors, pageAnchors, labels ->
pages.each { page ->
page.title = page.title.trim()
println page.title
def id = pushToConfluence page.title, page.body, page.parent, anchors, pageAnchors, labels
page.children*.parent = id
// println "Push children von id " + id
pushPages page.children, anchors, pageAnchors, labels
// println "Ende Push children von id " + id
}
}
def recordPageAnchor(head) {
def a = [:]
if (head.attr('id')) {
a[head.attr('id')] = head.text()
}
a
}
def promoteHeaders(tree, start, offset) {
(start..7).each { i ->
tree.select("h${i}").tagName("h${i-offset}").before('<br />')
}
}
def retrievePageIdByName = { String name ->
confluenceClient.retrievePageIdByName(name, confluenceSpaceKey)
}
def getPagesRecursive(Element element, String parentId, Map anchors, Map pageAnchors, int level, int maxLevel) {
def pages = []
element.select("div.sect${level}").each { sect ->
def title = sect.select("h${level + 1}").text()
pageAnchors.putAll(recordPageAnchor(sect.select("h${level + 1}")))
Elements pageBody
if (level == 1) {
pageBody = sect.select('div.sectionbody')
} else {
pageBody = new Elements(sect)
pageBody.select("h${level + 1}").remove()
}
def currentPage = [
title: title,
body: pageBody,
children: [],
parent: parentId
]
if (maxLevel > level) {
currentPage.children.addAll(getPagesRecursive(sect, null, anchors, pageAnchors, level + 1, maxLevel))
pageBody.select("div.sect${level + 1}").remove()
} else {
pageBody.select("div.sect${level + 1}").unwrap()
}
promoteHeaders sect, level + 2, level + 1
pages << currentPage
anchors.putAll(parseAnchors(currentPage))
}
return pages
}
def getPages(Document dom, String parentId, int maxLevel) {
def anchors = [:]
def pageAnchors = [:]
def sections = pages = []
def title = dom.select('h1').text()
if (maxLevel <= 0) {
dom.select('div#content').each { pageBody ->
pageBody.select('div.sect2').unwrap()
promoteHeaders pageBody, 2, 1
def page = [title : title,
body : pageBody,
children: [],
parent : parentId]
pages << page
sections = page.children
parentId = null
anchors.putAll(parseAnchors(page))
}
} else {
// let's try to select the "first page" and push it to confluence
dom.select('div#preamble div.sectionbody').each { pageBody ->
pageBody.select('div.sect2').unwrap()
def preamble = [
title: title,
body: pageBody,
children: [],
parent: parentId
]
pages << preamble
sections = preamble.children
parentId = null
anchors.putAll(parseAnchors(preamble))
}
sections.addAll(getPagesRecursive(dom, parentId, anchors, pageAnchors, 1, maxLevel))
}
return [pages, anchors, pageAnchors]
}
if(config.confluence.inputHtmlFolder) {
htmlFolder = "${docDir}/${config.confluence.inputHtmlFolder}"
println "Starting processing files in folder: " + config.confluence.inputHtmlFolder
def dir = new File(htmlFolder)
dir.eachFileRecurse (FILES) { fileName ->
if (fileName.isFile()){
def map = [file: config.confluence.inputHtmlFolder+fileName.getName()]
config.confluence.input.add(map)
}
}
}
config.confluence.input.each { input ->
// TODO check why this is necessary
if(input.file) {
input.file = confluenceService.checkAndBuildCanonicalFileName(input.file)
// assignend, but never used in pushToConfluence(...) (fixed here)
// #938-mksiva: assign spaceKey passed for each file in the input
spaceKeyInput = input.spaceKey
confluenceSpaceKey = input.spaceKey ?: config.confluence.spaceKey
confluenceCreateSubpages = (input.createSubpages != null) ? input.createSubpages : config.confluence.createSubpages
confluenceAllInOnePage = (input.allInOnePage != null) ? input.allInOnePage : config.confluence.allInOnePage
if (!(confluenceCreateSubpages instanceof ConfigObject && confluenceAllInOnePage instanceof ConfigObject)) {
println "ERROR:"
println "Deprecated configuration, migrate as follows:"
println "allInOnePage = true -> subpagesForSections = 0"
println "allInOnePage = false && createSubpages = false -> subpagesForSections = 1"
println "allInOnePage = false && createSubpages = true -> subpagesForSections = 2"
throw new RuntimeException("config problem")
}
confluenceSubpagesForSections = (input.subpagesForSections != null) ? input.subpagesForSections : config.confluence.subpagesForSections
if (confluenceSubpagesForSections instanceof ConfigObject) {
confluenceSubpagesForSections = 1
}
// hard to read in case of using :sectnums: -> so we add a suffix
confluencePagePrefix = input.pagePrefix ?: config.confluence.pagePrefix
// added
confluencePageSuffix = input.pageSuffix ?: config.confluence.pageSuffix
confluencePreambleTitle = input.preambleTitle ?: config.confluence.preambleTitle
if (!(confluencePreambleTitle instanceof ConfigObject)) {
println "ERROR:"
println "Deprecated configuration, use first level heading in document instead of preambleTitle configuration"
throw new RuntimeException("config problem")
}
File htmlFile = new File(input.file)
baseUrl = htmlFile
Document dom = confluenceService.parseFile(htmlFile)
// if ancestorName is defined try to find machingAncestorId in confluence
def retrievedAncestorId
if (input.ancestorName) {
// Retrieve a page id by name
retrievedAncestorId = retrievePageIdByName(input.ancestorName)
println("Retrieved pageId for given ancestorName '${input.ancestorName}' is ${retrievedAncestorId}")
}
// if input does not contain an ancestorName, check if there is ancestorId, otherwise check if there is a global one
def parentId = retrievedAncestorId ?: input.ancestorId ?: config.confluence.ancestorId
// if parentId is still not set, create a new parent page (parentId = null)
parentId = parentId ?: null
//println("ancestorName: '${input.ancestorName}', ancestorId: ${input.ancestorId} ---> final parentId: ${parentId}")
// #342-dierk42: get the keywords from the meta tags
def keywords = confluenceService.getKeywords(dom)
def (pages, anchors, pageAnchors) = getPages(dom, parentId, confluenceSubpagesForSections)
pushPages pages, anchors, pageAnchors, keywords
if (parentId) {
println "published to ${config.confluence.api - "rest/api/"}spaces/${confluenceSpaceKey}/pages/${parentId}"
} else {
println "published to ${config.confluence.api - "rest/api/"}spaces/${confluenceSpaceKey}"
}
}
}
""Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.