2 minutes to read
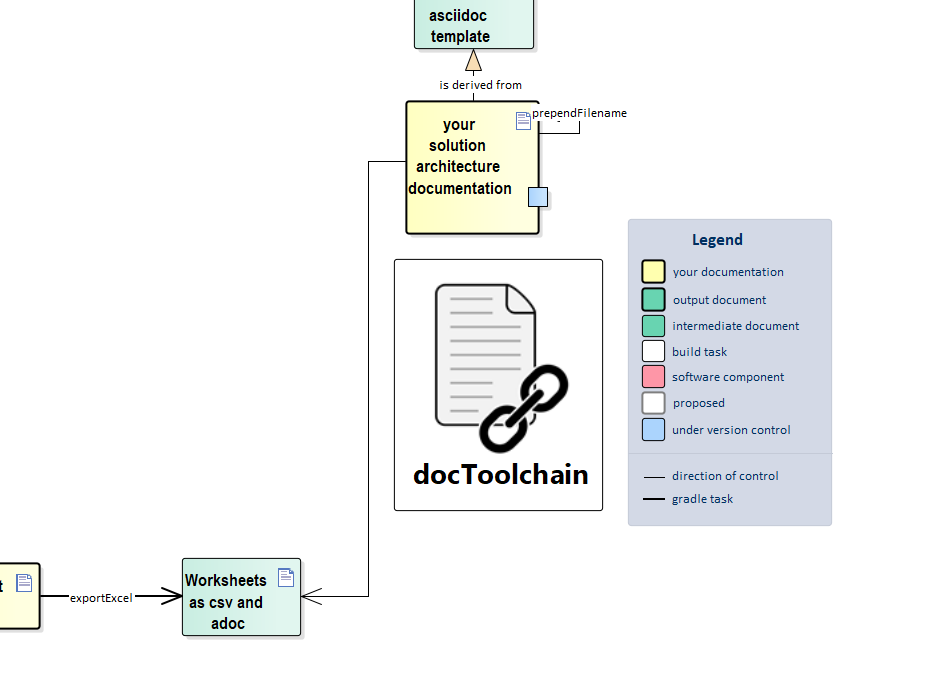
exportExcel
At a Glance
About This Task
Sometimes you need to include tabular data in your documentation.
Most likely, this data will be stored as a MS Excel spreadsheet, or you may like to use Excel to create and edit it.
Either way, this task lets you export an Excel spreadsheet and include it directly in your docs.
It searches for .xlsx files and exports each contained worksheet as .csv and as .adoc.
Note that formulas contained in your spreadsheet are evaluated and exported statically.
The generated files are written to src/excel/[filename]/[worksheet].(adoc|cvs).
The src folder is used instead of the build folder because a better history of worksheet changes is captured.
The files can be included either as AsciiDoc:
include::excel/Sample.xlsx/Numerical.adoc[]
…or as a CSV file:
[options="header",format="csv"] |=== include::excel/Sample.xlsx/Numerical.csv[] |===
The AsciiDoc version gives you a bit more control because the following are preserved:
-
Horizontal and vertical alignment.
-
col-span and row-span.
-
Line breaks.
-
Column width relative to other columns.
-
Background colors.
Further Reading and Resources
See asciidoctorj-office-extension to learn another way to use Excel spreadsheets in your docs.
Source
build.gradle
task exportExcel(
description: 'exports all excelsheets to csv and AsciiDoc',
group: 'docToolchain'
) {
doFirst {
File sourceDir = file(srcDir)
def tree = fileTree(srcDir).include('**/*.xlsx').exclude('**/~*')
def exportFileDir = new File(sourceDir, 'excel')
//make sure path for notes exists
exportFileDir.deleteDir()
//create a readme to clarify things
def readme = """This folder contains exported workbooks from Excel.
Please note that these are generated files but reside in the `src`-folder in order to be versioned.
This is to make sure that they can be used from environments other than windows.
# Warning!
**The contents of this folder will be overwritten with each re-export!**
use `gradle exportExcel` to re-export files
"""
exportFileDir.mkdirs()
new File(exportFileDir, '/readme.ad').write(readme)
}
doLast {
File sourceDir = file(srcDir)
def exportFileDir = new File(sourceDir, 'excel')
def tree = fileTree(srcDir).include('**/*.xlsx').exclude('**/~*')
def nl = System.getProperty("line.separator")
def export = { sheet, evaluator, targetFileName ->
def targetFileCSV = new File(targetFileName + '.csv')
def targetFileAD = new File(targetFileName + '.adoc')
def df = new org.apache.poi.ss.usermodel.DataFormatter();
def regions = []
sheet.numMergedRegions.times {
regions << sheet.getMergedRegion(it)
}
logger.debug "sheet contains ${regions.size()} regions"
def color = ''
def resetColor = false
def numCols = 0
def headerCreated = false
def emptyRows = 0
for (int rowNum=0; rowNum<=sheet.lastRowNum; rowNum++) {
def row = sheet.getRow(rowNum)
if (row && !headerCreated) {
headerCreated = true
// create AsciiDoc table header
def width = []
numCols = row.lastCellNum
numCols.times { columnIndex ->
width << sheet.getColumnWidth((int) columnIndex)
}
//lets make those numbers nicer:
width = width.collect { Math.round(100 * it / width.sum()) }
targetFileAD.append('[options="header",cols="' + width.join(',') + '"]' + nl)
targetFileAD.append('|===' + nl)
}
def data = []
def style = []
def colors = []
// For each row, iterate through each columns
if (row && (row?.lastCellNum!=-1)) {
numCols.times { columnIndex ->
def cell = row.getCell(columnIndex)
if (cell) {
def cellValue = df.formatCellValue(cell, evaluator)
if (cellValue.startsWith('*') && cellValue.endsWith('\u20AC')) {
// Remove special characters at currency
cellValue = cellValue.substring(1).trim();
}
def cellStyle = ''
def region = regions.find { it.isInRange(cell.rowIndex, cell.columnIndex) }
def skipCell = false
if (region) {
//check if we are in the upper left corner of the region
if (region.firstRow == cell.rowIndex && region.firstColumn == cell.columnIndex) {
def colspan = 1 + region.lastRow - region.firstRow
def rowspan = 1 + region.lastColumn - region.firstColumn
if (rowspan > 1) {
cellStyle += "${rowspan}"
}
if (colspan > 1) {
cellStyle += ".${colspan}"
}
cellStyle += "+"
} else {
skipCell = true
}
}
if (!skipCell) {
switch (cell.cellStyle.getCellAlignment().getHorizontal().toString()) {
case 'RIGHT':
cellStyle += '>'
break
case 'CENTER':
cellStyle += '^'
break
}
switch (cell.cellStyle.getCellAlignment().getVertical().toString()) {
case 'BOTTOM':
cellStyle += '.>'
break
case 'CENTER':
cellStyle += '.^'
break
}
color = cell.cellStyle.fillForegroundXSSFColor?.RGB?.encodeHex()
color = color != null ? nl + "{set:cellbgcolor:#${color}}" : ''
data << cellValue
if (color == '' && resetColor) {
colors << nl + "{set:cellbgcolor!}"
resetColor = false
} else {
colors << color
}
if (color != '') {
resetColor = true
}
style << cellStyle
} else {
data << ""
colors << ""
style << "skip"
}
} else {
data << ""
colors << ""
style << ""
}
}
emptyRows = 0
} else {
if (emptyRows<3) {
//insert empty row
numCols.times {
data << ""
colors << ""
style << ""
}
emptyRows++
} else {
break
}
}
targetFileCSV.append(data
.collect {
"\"${it.replaceAll('"', '""')}\""
}
.join(',') + nl, 'UTF-8')
// fix #1192 https://github.com/docToolchain/docToolchain/issues/1192
// remove unnecessary spans which break Asciidoctor rendering
def prev = ''
def removed = []
def useRemoved = true
style.eachWithIndex { s, i ->
if (s!="skip") {
if (s.contains('+')) {
def span = s.split('[+]')[0].split('[.]')
def current = ""
if (span.size()>1) {
current = span[1]
}
if (span[0] != '') {
removed << span[0] + '+' + s.split('[+]')[1]
} else {
removed << s.split('[+]')[1]
}
if (i > 0) {
if (current != prev) {
useRemoved = false
}
}
prev = current
} else {
removed << s
useRemoved = false
}
} else {
removed << "skip"
}
}
if (useRemoved) { style = removed }
// fix #1192 https://github.com/docToolchain/docToolchain/issues/1192
targetFileAD.append(data
.withIndex()
.collect { value, index ->
if (style[index] == "skip") {
""
} else {
style[index] + "| ${value.replaceAll('[|]', '{vbar}').replaceAll("\n", ' +$0') + colors[index]}"
}
}
.join(nl) + nl * 2, 'UTF-8')
}
targetFileAD.append('|===' + nl)
// rewrite file to remove consecutive nl
targetFileAD.write(targetFileAD.text.replaceAll("(?m)(\\r?\\n){2,}", nl+nl))
}
tree.each { File excel ->
println "file: " + excel
def excelDir = new File(exportFileDir, excel.getName())
excelDir.mkdirs()
InputStream inp
inp = new FileInputStream(excel)
def wb = org.apache.poi.ss.usermodel.WorkbookFactory.create(inp);
def evaluator = wb.getCreationHelper().createFormulaEvaluator();
for (int wbi = 0; wbi < wb.getNumberOfSheets(); wbi++) {
def sheetName = wb.getSheetAt(wbi).getSheetName()
println " -- sheet: " + sheetName
def targetFile = new File(excelDir, sheetName)
export(wb.getSheetAt(wbi), evaluator, targetFile.getAbsolutePath())
}
inp.close();
}
}
}Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.